Accessing Power BI Datasets via XMLA Endpoint in Python Jupyter Notebook
In this blog post I show how you can use Python to access datasets published to Power BI service using Python in Jupyter Notebook



Power BI recently announced availability of a new license 'Premium Per User' which will allow small to medium size companies to access Premium features at a lower price point (as of 12/11/2020 price has not been published) . I was given a priority access to it and have been exploring all the premium features for the last few weeks. One of the key benefits of Premium is the ability to consume published datasets via XMLA endpoint. Instead of me describing it, you can read Microsoft's documentation for detailed description here.
To use XMLA endpoint, you will need to have a Premium workspace and enable the 'XMLA Endpoint' in capacity settings.
Capacity Settings > Power BI Premium > Workloads > XMLA Endpoint
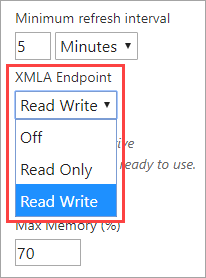
In this blog post I will show how to setup connection to the XMLA endpoint and access Power BI datasets & measures within those datasets using Python in a Jupyter notebook. This blog post is written in a Jupyter notebook. I use Jupyter notebooks for data exploration, visualization and building machine learning models. Ability to consume published datasets in a notebook will be immensely helpful in my own workflow.
I took inspiration from David Elderveld's amazing 4-part blogposts on 'Jupyter as an External Tool for Power BI Desktop'. It really opened up lot of options that I didn't know existed, thanks David! I highly encourage you to read all the four posts to learn more about using Python with Power BI.
Secondly, none of this would be possible without the python-ssas module by Josh Dimarsky which enables TOM connection to Analysis Services.
To get started, you will need three things:
- install the pythonnet library (
pip install pythonnet) - Make sure you have
Microsoft.AnalysisServices.Tabular.dllandMicrosoft.AnalysisServices.AdomdClient.dlldlls. If you use Excel, Power BI, you will most likley already have them. As Josh mentions in his documentation, they are usually installed inC:\Windows\Microsoft.NET\assembly\GAC_MSIL - copy the
ssas_api.pyfile from here and save it in your Python libraries folder or Jupyter working directory.
import pandas as pd
import ssas_api as ssas
import seaborn as sns
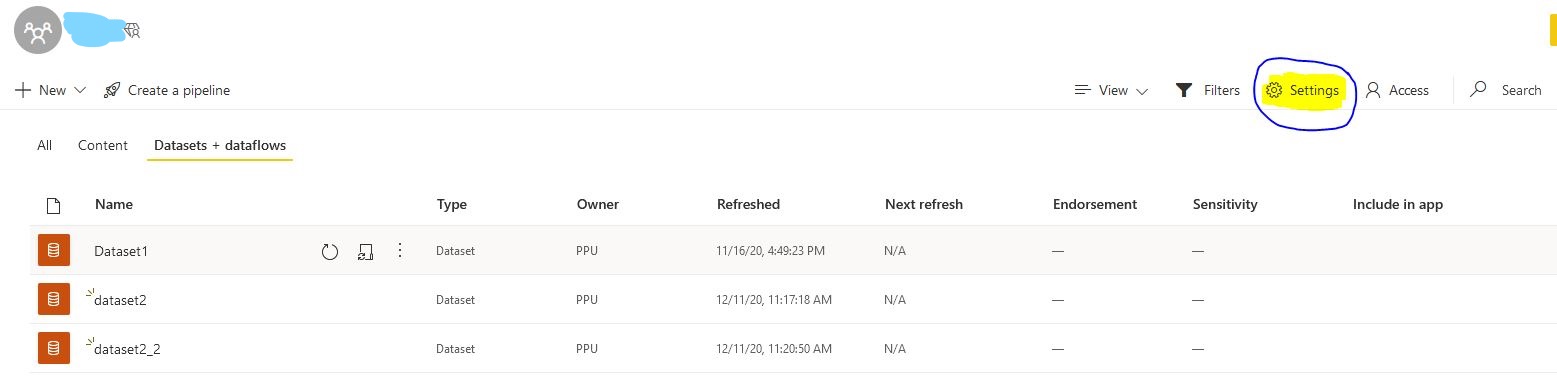
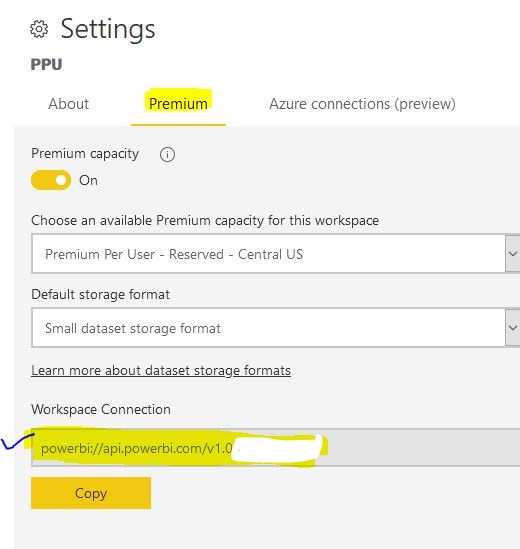
First we want to connect to our Power BI service account & the Premium workspace. You will need to find the workspace connection string URL. It will be in this format powerbi://api.powerbi.com/v1.0/[tenant name]/[workspace name]. You can obtain it from your workspace settings (see below)
First go to your Premium Workspace and click on Settings. Notice that I have three datasets in this workspace, viz Dataset1, dataset2 and dataset2_2.
Next, copy the server address from Workspace Connection:
Create variables for your tenant username and password
server = 'workspace_connection_from_above'
username = 'name@email.com'
password = 'password'
Setup connection string by specifying the server name, username & password. Note that I have left the database name (db_name) blank here because I am assuming that we don't know the names of the datasets that are available in this workspace. We will explore the workspace and get a list of all the datasets. If you already know the dataset name, you can enter it between the single quotations.
conn1 = ssas.set_conn_string(
server=server,
db_name='',
username=username,
password=password
)
Import libraries for Tabular Object Model (TOM) and setup the TOM server. As long as your username and password are valid, you will connect to your workspace using TOM. If it fails, it means either your credentials are incorrect or you do not have access to the workspace. You will not be prompted for interactive authentication.
global System, DataTable, AMO, ADOMD
import System
from System.Data import DataTable
import Microsoft.AnalysisServices.Tabular as TOM
import Microsoft.AnalysisServices.AdomdClient as ADOMD
try:
TOMServer = TOM.Server()
TOMServer.Connect(conn1)
print("Connection to Workspace Successful !")
except:
print("Connection to Workspace Failed")
Let's now get a list of all the avaible datasets in this workspace and their metadata such as compatibility level, database id, size in megabytes, creation date and last update date.
datasets = pd.DataFrame(columns=['Dataset_Name', 'Compatibility', 'ID', 'Size_MB','Created_Date','Last_Update' ])
for item in TOMServer.Databases:
datasets = datasets.append({'Dataset_Name' :item.Name,
'Compatibility':item.CompatibilityLevel,
'Created_Date' :item.CreatedTimestamp,
'ID' :item.ID,
'Last_Update' :item.LastUpdate,
'Size_MB' :(item.EstimatedSize*1e-06) },
ignore_index=True)
datasets
I have three datasets in this workspace but I only see 2! dataset2 and dataset2_2 are identical except dataset2 was created by uploading the csv file to the worspace while the other two datasets were published to the workspace from Power BI Desktop. Also note that their compatibility levels are different. Dataset1 was published with the old version of Power BI Desktop with 'Enhanced Metadata' option turned off that's why its compatibility level is not 1520. Since September 2020 release, Power BI Desktop automatically converts the datasets to Enhanced Metadata.
Now let's choose the dataset we want to connect to. In this case I want to access dataset2_2. I will copy the database id from the ID column from the above table. Then we will find the names of all the tables that are available in that dataset.
ds = TOMServer.Databases['a93244fe-860d-45c2-9d36-b44fb284c54d']
for table in ds.Model.Tables:
print(table.Name)
In the dataset2_2 dataset, the only available table is dataset2. Let's connect to this table. We will create a new connection string by specifying the db_name this time.
conn2 = (ssas.set_conn_string(
server=server,
db_name='dataset2_2',
username = 'name@email.com',
password = 'password'
))
You can write any valid DAX query against this table and get the results back as a Pandas dataframe.
dax_string = '''
//Write your DAX Query here
EVALUATE
dataset2
'''
df_dataset2 = (ssas
.get_DAX(
connection_string=conn,
dax_string=dax_string)
)
df_dataset2.head()
sns.boxplot(df_dataset2['dataset2[totalAmount]'])

We can also get a list of all the measures and their DAX expressions. As seen below, in this table we have only one measure called totalAmount average per vendorID with its DAX.
table = ds.Model.Tables.Find('dataset2')
for measure in table.Measures:
print(measure.Name, ":\n", measure.Expression)
Based on this Microsoft documentation, I was under the impression that only the datasets with Compatibility level 1500 or higher could be accessed via XMLA. That's not the case. Dataset1 has a compatibility of 1465 and can still be accessed via XMLA endpoint as seen below.
conn3 = (ssas.set_conn_string(
server=server,
db_name='Dataset1',
username = 'name@email.com',
password = 'password'
))
dax_string2 = '''
//Write your DAX Query here
EVALUATE
KeyInfluencers_Predictors
'''
df_dataset1 = (ssas
.get_DAX(
connection_string=conn3,
dax_string=dax_string2)
)
df_dataset1.head()
Datasets in Power BI service can currently be accessed via number of different tools (SSDT, SSMS, PowerShell, Tabular Editor, DAX Studio, ALM Toolkit) which are all database modeling tools. But Data Scientists now can easily access the datasets for exploring the data and building machine learning models in Jupyter Notebook or VSCode using Python.
This method can also be used to export multiple refreshed dataset(s) on a schedule and on demand.
There are still few things I am not sure about and need to explore more.
- Can I use service principal, key etc so I don't have to write username/password in my code
- How to write back, create dataset using Python and push it to the workspace
- Can I create/modify measures?
- What are the limitations ?
Please feel free to post your comments below or reach out to me if you find any errors or have suggestions.
References:
- https://dataveld.com/2020/07/20/python-as-an-external-tool-for-power-bi-desktop-part-1/
- https://powerbi.microsoft.com/en-us/blog/power-bi-premium-per-user-public-preview-now-available/
- https://github.com/yehoshuadimarsky/python-ssas/
- https://docs.microsoft.com/en-us/power-bi/admin/service-premium-connect-tools
- https://docs.microsoft.com/en-us/analysis-services/tom/introduction-to-the-tabular-object-model-tom-in-analysis-services-amo?view=asallproducts-allversions
- https://docs.microsoft.com/en-us/dotnet/api/microsoft.analysisservices.tabular.measure?view=analysisservices-dotnet