The Magic of SHD
A simple yet fast and powerful forecasting algorithm



SHD stands for (S)ingle Exponential Smoothing, (H)olt's, (D)amped forecasting algorithm. It's not often that you can describe the entire algorithm in one single sentence but I just did that. And this simple algorithm often outperforms some of the most complex forecasting algorithms including DNNs and FB Prophet on univariate low frequency time series. I have used it on many projects successfully with great results. I am sharing it because the great Spyros Makridakis reminded on twitter that SHD was found superior in all M (M5 would be an exception) competitions.
The simple arithmetic average of Single, Hold and Damped exponential smoothing often used as a benchmark to compare the forecasting accuracy of methods. @stephensenn https://t.co/WduPWioPvI
— Spyros Makridakis (@spyrosmakrid) March 8, 2021
Not many know about this gem so I thought I would share my code. It's a reminder that you don't always need complex algorithms to create forecast predictions. Use what's simple and parsimonious.
How does it work?
Just take arithmatic mean of forecast from SES, Holt's and Damped
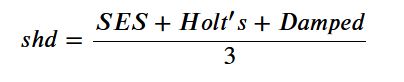
How does it stack against other algorithms?
Read it yourself. It worked as good and even better than most other algorithms in the M3 competition. It works particularly well with low frequency time series (Yearly, monthly). It works well because we are ensembling three different algorithms. It's been shown that forecast combinations often outperform single best models.
I will demonstrate it using an example below. This is the same dataset I used in my two previous blogs.
import pandas as pd
import numpy as np
import statsmodels.api as sm
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
import statsmodels
from statsmodels.tsa.statespace.exponential_smoothing import ExponentialSmoothing
import scipy
from scipy.stats import boxcox
from scipy.special import inv_boxcox
from statsmodels.tools.eval_measures import rmse
print('Pandas:', pd.__version__)
print('Statsmodels:', sm.__version__)
print('Scipy:', scipy.__version__)
print('Numpy:', np.__version__)
def combshd(train,horizon,seasonality, init):
# Author: Sandeep Pawar
# Date: 8/30/2020
# version: 1.1
'''
params
----------
:train numpy array or Pandas series with univariate data
:horizon forecast horizon (int)
:seasonality For monthly 12, yearly 1, quarerly 4 (int)
:init initialization ('heuristic','concentrated')
output
------------
numpy array if length equal to specified horizon
'''
train_x,lam = boxcox (train)
ses=(sm.tsa.statespace.ExponentialSmoothing(train_x,
trend=True,
seasonal=None,
initialization_method= init,
damped_trend=False).fit())
fc1 = inv_boxcox(ses.forecast(horizon),lam)
holt=(sm.tsa.statespace.ExponentialSmoothing(train_x,
trend=True,
seasonal=seasonality,
initialization_method= init,
damped_trend=False).fit())
fc2 = inv_boxcox(holt.forecast(horizon),lam)
damp=(sm.tsa.statespace.ExponentialSmoothing(train_x,
trend=True,
seasonal=seasonality,
initialization_method= init,
damped_trend=True).fit())
fc3 = inv_boxcox(damp.forecast(horizon),lam)
fc = (fc1+fc2+fc3)/3
return fc
data = pd.read_csv("https://raw.githubusercontent.com/pawarbi/datasets/master/timeseries/ts_frenchretail.csv")
data['Date']= pd.to_datetime(data['Date'])
data.set_index('Date', inplace= True)
train = data.iloc[:-4]
test = data.iloc[-4:]
data.head()
data.plot();

print("Train legth:", len(train), "\nTest legth:",len(test))
assert len(data)==len(train) + len(test)
shd_pred = combshd(train = train['Sales'].values,horizon=len(test),seasonality = 4, init = 'heuristic')
rmse(test['Sales'].values,shd_pred ).round(0)
RMSE using SHD is 63734. For comparison, FB Prophet gave ~66,000 and SARIMA) was ~82,000. I was able to further improve this by ensembling many algorithms but still it's impressive that with just few lines of code you can create a sophisticated algorithm !
A reminder, always start with baseline simple algorithms. In practice, fast and frugal wins the long race.