Introduction to Azure ML SDK
Presentation notebook from 'Azure Saturday, Hamburg 2021' event.



- Azure Saturday Hamburg, Feb 20, 2021
- Agenda
- Motivation
- Azure ML Service

Note: This notebook was presented at Azure Saturday Hamburg
Motivation
Before I talk about Azure ML, I would like to first provide some motivation for why we want to learn and use Azure ML.
The goal of this presentation is not to show how to create machine learning models but rather, how to use Azure ML to operationalize the machine learning models at scale. I will create an example machine learning model but really the focus is understanding the common 'design patterns' in Azure ML. If you are familiar with theory of machine lerning, this presentation/example notebook will help you understand the often neglected MLOps part of ML. If you do not have experience with creating ML models or are new to Python/Azure, focus on the logical process rather than the exact mechanics. You can always revisit this example notebook or Microsoft Learn but hopefully from this session you will understand, at a high-level, how to use Azure ML to deploy ML models in production.
Machine Learning Process - As Advertised
Let's start with a typical machine learning process. You will see plenty of tutorials on how to create machine learning models. Just type in "Machine learning process" in Google and you will see below results. Most of these describe the process broadly as follows:
- Obtain data
- Clean data
- EDA
- Preprocess the data
- Build model(s)
- Validate the model
- Serialize the model
Let's follow this process to build a model.
Data
I will use a dataset from UCI Machine Learning reporsitory called "Bank Marketing Data Set". You may have seen this in many tutorials. I chose this dataset because the focus of this presentation is learning Azure ML so I wanted to pick something that most can understand and I recently gave a presentation on Machine Learning Model Interpretability using the same dataset. In case you are interested in that topic, you will already be familiar with this dataset after this presentation.
This dataset has 20 features, mix of numerical and categorical features, and a target label with "Yes/No" values. It's a binary classification problem and the goal is to predict if a customer will sign up for a bank term deposit. Feel free to explore the dataset on your own before proceeding.
#collapse-hide
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score, accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder, FunctionTransformer, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn import metrics
from interpret import show
from interpret.perf import ROC
from sklearn import metrics
import seaborn as sns
print(pd.__version__)
#https://archive.ics.uci.edu/ml/datasets/Bank+Marketing
path = "https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/bankmarketing_train.csv"
data = pd.read_csv(path)
print(data.shape)
data.head()
#Define functions to clean the data
def clean_col_names(df):
df.columns = [col.replace('.','_') for col in df.columns]
return df
def clean_dtype(df):
cat_cols = ['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
for col in cat_cols:
df.loc[:,col] = df[col].astype('category')
return df
def binarize_y(y):
y = (y=='yes').astype(int)
return y
#Copy and Clean the data
df = data.copy()
df = clean_col_names(df)
df = clean_dtype(df)
df.head(3)
Before conducting the exploratory data analysis (EDA), we will split the data into train and test. EDA should always be performed on the training data only to prevent information leakage, i.e overfitting. Test set should be used for final model evaluation.
Quick note - I have dropped the duration column because based on my analysis explained here, this feature leaks information so I am dropping it. Watch the presentation if you would like to understand how creating interpretable models can help avoid such data leakage.
X = df.drop(['y','duration'], axis=1)
y = df.y
y = binarize_y(y)
cat_cols = ['job','marital','education','default','housing','loan','contact','month','day_of_week','poutcome']
num_cols = list(set(X.columns)-set(cat_cols))
x1,x2, y1,y2 = train_test_split(X,y, stratify=y, train_size=0.80, shuffle=True, random_state = 0)
print("Training set:",len(x1),"\nTest set:",len(x2))
Training set has 26,360 observations and test has 6590 observations. The 80/20 split is arbitrary at this point. You can create learning curves to figure out how much data you need for training. It will also depend on the algorithm you are using.
x1.head(3)
Exploratory Data Analysis
The data is clean for our demonstration purposes. Before building the model, you should invest significant time in understanding the data first. This is definitely the most important part of building a reliable machine learning model. In this demo, I am going to skip this step and leave it up to you.
#For demonstration, using only few numerical columns and 1000 random observations
sns.pairplot(x1[['emp_var_rate','cons_price_idx','cons_conf_idx','euribor3m']].sample(1000),diag_kind='kde');

print((y1.value_counts(normalize=True)))
(y1.value_counts(normalize=True)).plot(kind='bar');

In the bar chart above, 1 is 'yes' and 0 is 'no'. As you can see, ~89% customers did not sign up for the term deposit and 11% did. Thus, the target labels are not balanced (i.e not ~50/50%). This will affect the model performance metric we choose. For imbalanced dataset, using accuracy as the metric can lead to incorrect results. ROC-AUC is often used in such situations. This is a big topic so for now we just need to know that based on the EDA we see that the target is imbalanced and we will have to keep it in mind when building the model.
In the previous steps we split the data and now we are ready to build the ML pipeline. We build the preprocessing pipeline for catgorical and numerical columns using Pipeline() from sklearn.
Categorical columns will be encoded using OneHotEncoder and numerical features will be scaled using StandardScaler. Standard scaler will bring all numerical features to mean = 0 and std dev = 1. There are various ways of encoding and scaling but for demo purposes we will stick with this.
Also note that not all ML algorithms need encoding and scaling. Linear methods such as Logistic Regression do while tree-based algorithms (Random Forest, GBMs) don't. We will still preprocess the data so we can use the same pipeline for different algirithms, if needed.
#Get column index for each of the columns types
cat_nums = [list(x1.columns).index(col) for col in cat_cols]
num_nums = [list(x1.columns).index(col) for col in num_cols]
print(cat_nums)
print(num_nums)
#One hot encode
cat_ohe_step = ('ohe', OneHotEncoder(sparse=False,
handle_unknown='ignore'))
#Build Pipeline
cat_pipe = Pipeline([cat_ohe_step])
num_pipe = Pipeline([('std', StandardScaler())])
transformers = [
('cat', cat_pipe, cat_nums),
('num', num_pipe, num_nums)
]
ct = ColumnTransformer(transformers=transformers)
ct
Visualize the preprocessing steps:
#Visualize the Preprocessing steps
from sklearn import set_config
set_config(display='diagram')
ct
Build the model
I am going to use Random forest algorithm. Random Forest often gives a good baseline performance right out of the box in most scenarios without overfitting. Also, Random Forest has a nice feature - 'Out of Bag' (OOB) score. It will help us estimate model performance over multiple bootstrapped samples thus providing a good proxy for cross-validation performance. I am using OOB here, just to save model building time. In a real project, you will carefully construct a CV scheme.
We use the above pipeline of transformations with the Random Forest estimator with default parameters. Set the oob_score=True to get the OOB score. Also, class_weight is set to balanced to mitigate class imbalance.
pipe = Pipeline([
('ct', ct),
('rf', RandomForestClassifier(oob_score=True,
random_state=0,
class_weight = 'balanced')),
])
#Fit the model
pipe.fit(x1,y1)
#Access the RF estimator from the pipeline
rf = pipe[-1]
# OOB, by default, gives Accuracy score. This is a slightly imbalanced dataset,
# so we will calculate AUC on OOB predictions
oob_pred = np.argmax(rf.oob_decision_function_,axis=1)
auc1 = metrics.roc_auc_score(y1, oob_pred)
print("OOB AUC is: ",np.round(auc1,2))
print("OOB AUC on test set is: ",np.round(roc_auc_score(y2, pipe.predict(x2)),2))
Although the AUC is not very high, OOB gave an excellent estimation of the test score. We are happy with the model and it's ready to be used for future predictions.
Serialize the model using joblib
import joblib
joblib.dump(pipe, 'baseline_rf.pkl')
Test the pickle file on the test set again to make sure it's working as expected.
joblib.load('baseline_rf.pkl').predict(x2)
Success !
We followed the entire process that's laid out in the 'typical' machine learning process. But is that how it works in real life?
The answer is - A Resounding NO.
This is in fact just the fraction of the actual process. In reality it's very convoluted, non-linear process with multiple stakeholders/teams involved in creating the final model. You have business stakeholders defining the goals and business objectives, IT/Data Engineers who work on extracting/staging the data, Data scientist creating the models, software engineers integrating it with the product and business intelligence developers consuming the predictions in a dashboard. All these teams collaborate with each other, going through many iterations before finalizng a model.
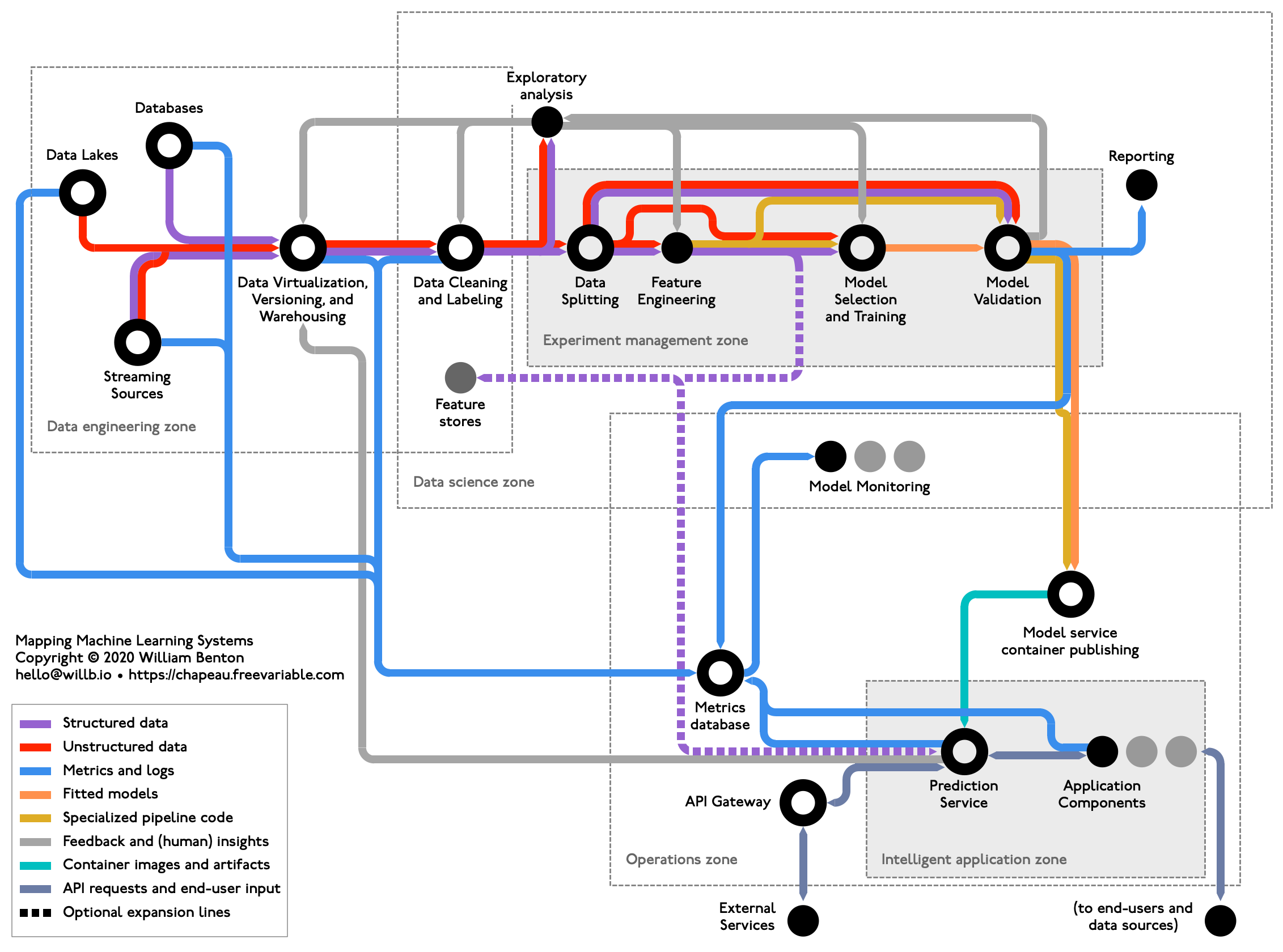
Ref: https://chapeau.freevariable.com/static/202010/mlops-tube.png
Things that are missing from this 'Typical' process are:
- Multiple stakeholders and collaborators. Identifying business objectives and tying it to model metric
- Computational resources needed to run the ML models. If you are working on a dataset with millions of rows or a DNN model, you will very likely need GPUs
- Experimentation design: algorithms, preprocessing steps, feature selection, feature engineering. You will create 1000s of models before identifying few model candidates that meet the business objectives.
- Experiment tracking: You will need to efficiently track these 1000s of ML experiments to understand the patterns
- Data versioning: You will work with several different versions of the data. By the time you arrive at the final model, the data used for training & evaluating that model will be very different from what you started with. You or your colleagues will need to use a different version of that data for som eother project.
- Track model artifacts: Each model will have its dependency requirements, input/output schema, hyper parameters
- Package the model: Containerize the model with the dependendencies
- Deploy & monitor: scale, data security, performance monitoring, data drift, model interpretability
This is where Azure Machine Learning Service helps! It's a fully managed cloud service that lets you:
- Work in collaboration while giving control on data security and resources
- Scale the compute targets as needed
- Track data and model versions
- Experiment with thousands of models and keep track of them
- Deploy the models based on requirements (real-time, batch, IoT)
- Monitor in production
- Trace the model back to data and model artificats
- DevOps
Azure ML is a Fully managed MLOPS Platform that will help you manage the machine learning process based on project requirements.
Hopefully above example gave you reasons to learn and understand why MLOps is important. With Scikit-learn you can create the models but it won't help you put those models in production. We will now see how to operationalize this model using Azure ML.
Create a free Azure account by visiting the Azure page: https://azure.microsoft.com/en-us/services/machine-learning/ The account is free and you get $200 credit for the first 30 days. Create a 'Pay-As-You-Go' subscription so you will incur costs for only the services you use. Be careful of creating compute resources. Shut them down when you are not using them to avoid a costly surprises. If you are a student, you may get some additional benefits.
Create Azure ML Resource
From MS Docs: A resource group is a container that holds related resources for an Azure solution. The resource group can include all the resources for the solution, or only those resources that you want to manage as a group. You decide how you want to allocate resources to resource groups based on what makes the most sense for your organization. Generally, add resources that share the same lifecycle to the same resource group so you can easily deploy, update, and delete them as a group.
The resource group stores metadata about the resources. Therefore, when you specify a location for the resource group, you are specifying where that metadata is stored. For compliance reasons, you may need to ensure that your data is stored in a particular region.
 Ref:
Ref: You can access and manage these resources in Azure ML studio using GUI. Some of these resources can also be managed using Azure ML SDK. As you create machine learning models, you will need to access these resources based on project requirements. The Python sdk will allow you to access them in your notebook on the fly. If the resources don't exist, you can create them programmatically.
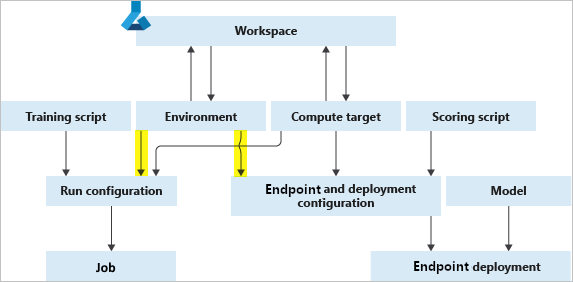
Architecture

I highly recommend creating a virtual enviroment that's specific to Azure ML projects to manage dependencies, especially for Azure Auto ML. Azure AutoML dependencies are often hard to resolve.
Create a virtual enviroment (e.g evenv) and install Azure ML : pip install --upgrade azureml-sdk[notebooks,automl].
You can read more here
print("I am working with, Azure ML sdk ver: ",azureml.core.VERSION)
| Feature | Description | Class |
|---|---|---|
| Workspace | Foundational resource in the cloud to manage experiments, models |
Workspace(..) |
| Compute Instance | Fully managed development environment (DVSM) | ComputeInstance(..) |
| Compute Cluster | Fully managed multi-node, scaleable compute | ComputeTarget(..) |
| Datastore | Azure Data storage | Datastore(..) |
| Dataset | Abstracted File or Tabular data stored in Datastore | Dataset(..) |
| Experiment | ML Experiment folder | Experiment(..) |
| Run | An instance of an experiment with artifacts | Run(..) |
| Log | Log metrics, artifacts related to run | Environment(..) |
| Environment | Package environment and dependencies | .log(..) |
| ScriptRunConfig | Configuration to run experiments | ScriptRunConfig(..) |
| Model | Manage, register, deploy models in the cloud | Model(..) |
| Webservice | Containerized packages for deployment, Endpoints | Webservice(..) |
You may have different workspaces for different teams, projects etc. In fact, it's recommended to create different resource groups so all the project data, metadata, artifacts remain in that workspace. Especially if you are just trying Azure ML so you can just delete that resource without incurring any charges for any resources in the future. To create or access a workspace, we use Workspace() class. The easiest way is to download the config.json file from the resource group to your working directory. It has all the tenant, subscription information to connect to that workspace. You will be prompted to authenticate your credentials.

from azureml.core import Workspace
print("Connecting to the Workspace....", end="",sep='\n')
ws = Workspace.from_config()
print("\nWorkspacename:",ws.name, ", \nWorkspace location:", ws.location)
We are connected to the workspace, now we can access the assets and artifacts in this workspace
When the ML resource was created, Azure automatically created and attached a Blob storage to this workspace. That's the power of managed resources ! You can always attach other Blob, ADLSg2 storage accounts as needed. Let's access this default datastore.
# List all datastores registered in the current workspace
datastores = ws.datastores
for name, datastore in datastores.items():
print(name, datastore.datastore_type)
We have two blog storage accounts in this workspace. Let's conenct to the default datastore.
datastore = ws.get_default_datastore()
datastore
Remember this is the 'datastore'. We haven't accessed any datasets in this datastore yet. Your data engineering team, for example, can do ETL using ADF, Synapse Analytics, Power Query etc. for you and register a dataset in this datastore.You can also add other datasets to this datastore. We will register the current bank marketing data to this datastore. Once registered, your other team members can access this dataset by just pointing to that dataset.
Sometimes you may find it easier to use the GUI in the Azure ML studio to register a dataset. The GUI is more interactive and can also generate dataset profile.
Although it may not seem like a big deal, but being able to register, track, version the datasets seamlessly is one of the most important steps in creating reliable machine lerning models. In the model creation process, you will generate different versions of the data. By versioning and tracking, you will be able to trace which dataset was used for the training the deployed model and thus debug the models in production.
Don't take my work for it. See what renowned ML researchers, Andrew Ng and Francois Chollet (creator of Tensfor Flow), say about importance of data collection, versioning. Ref
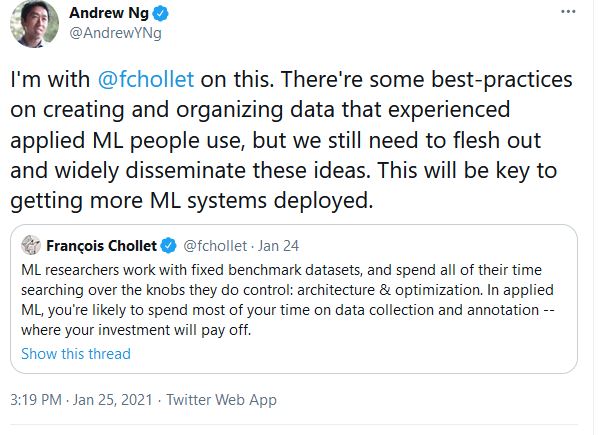
Following DataOps ptactices will pay rich dividends and avoid many headaches when yu have to debug and re-train models in the future.
The dataset you create in Azure ML is actually an abstraction/reference to the stored data and its metadata (ref). The datasets are lazily evaluated, which means:
- No additional storage cost
- Data versioning
- No risk of changing original data
from azureml.core import Dataset
from azureml.data.dataset_factory import DataType
#First create a dataset object
ds1 = Dataset.Tabular.from_delimited_files(path=path)
#Register this dataset to the datastore
print("Registering dataset to the cloud...", end="")
ds1 = ds1.register(workspace = ws,
name= "bankmarketing",
description = "This is the original data")
print("\n\nData registration successful\n\n", Dataset.get_all(ws) )
We have registered the original dataset to the default datastore.
ds2 = ds1.drop_columns('duration')
ds2 = ds2.register(workspace = ws,
name= "bankmarketing",
description = "Duration column dropped",
create_new_version=True)
Dataset.get_all(ws)
Note that we still have only 1 dataset in the Datastore. We just replaced the first dataset with the new version. Notice the version number version=2 above. We can retrieve any version when needed. We have only 1 file in the datastore not 2. This is how, by creating abstraction, we are able to save storage cost. If needed, you can add properties, tags, description to the dataset for future reference. In fact it's a good practice to do so for tracebility.
By default when you reference a dataset, it will always pull the latest version, unless specified.
We are still not done with the dataset. For training, we cleaned the data and split it into train/test. Those also need to be registered to the datastore. We don't have to but that's good DataOps/MLOps practice. Also, anytime you create a cross-validation folds for your final model training/validation, register those in the datastore too for reproducibility. To keep things simple, I am going to upload the train and test data created above to the datastore as one single csv file. Also note that you can directly register a pandas dataframe as a dataset.
#Create one single file with training and testing data
#Add a column to label which data is train and test
#This way we can keep the data in one single file
# Besure sure to drop the 'data' columns before training and testing.
train = x1.copy()
train['target'] = y1
train['data'] = 'train'
test = x2.copy()
test['target'] = y2
test['data'] = 'test'
train_test_data = train.append(test)
# Register the pandas dataframe as a dataset
# Add tags for traceability
from azureml.data.dataset_factory import TabularDatasetFactory
ds3 = (TabularDatasetFactory
.register_pandas_dataframe(
train_test_data,
target=(datastore,'bank_train_test'),
name='bank_train_test',
tags = {'Author':'Sandeep','Project':'Bank Marketing'},
show_progress=True)
)
for dataset in Dataset.get_all(ws):
print(dataset)
Just for illustration purposes, if we want to retrieve a dataset by name, we can use the get_by_name() method. We can also see the id (i.e unique id) for the dataset. We will log this as an artifact during model building so we can trace the exact train/test used for future reference.
Dataset.get_by_name(ws, 'bank_train_test')
ds_uid = '7b81a6c0-1e72-4948-86bb-ddac0e4e5d77'
Datastore has two datasets now which can be accessed anytime or versioned.
We can train the model locally and deploy it to the cloud. But if you want to scale-up the process by parallelizing model training, you can use the compute cluster. There two types of compute:
-
Compute Instance: This is like a managed VM with R,Python, Jupyter installed. You can use it for remote training but can also be accessed from the Studio for development.
-
Compute Cluster: This is a scalable multi-node compute, meaning if your training requires lot of compute power (e.g. 12 machines with 24 cores each) you can push the training to the compute cluster to do that. This can also be used for batch-inferencing.
For example purposes, I will show how to create it but won't use it. Compute is expensive. Companies often create compute quota to limit cost and use remote compute for hyperparameter tuning or large jobs. Note that if you are using Azure ML pipelines, you have to use Compute instance/cluster and local training is not available.
I generally prefer creating compute using GUI because you can see the cost of each compute option.
from azureml.core.compute import ComputeTarget, AmlCompute
compute_name = "DS12V2"
try:
vm = ComputeTarget(ws, compute_name)
print(f"{compute_name} exists already")
except:
compute_config = AmlCompute.provisioning_configuration(vm_size="Standard_D2_V2", max_nodes=4)
vm = ComputeTarget.create(ws, compute_name, compute_config)
vm.wait_for_completion(show_output=True)
This is the heart of machine learning and where all the magic happens. When you are working on a machine learning project, it's rarely a linear process as we discussed above. You try many different algorithms, debug them, understand how they work, try different preprocessing steps, feature engineering, data augmentation etc,, which means you will end up creating thousands of models per project. To keep track of all these experimental runs, Azure ML provides the Experiment class.
Think of Experiment() as a big giant folder where you save the model runs and the artifacts associated with that experiment. At the end of your experiment, you will see how each model performed based on selected metric and choose the right model for your project. The steps you will follow for each experimental run:
- Create Experiment object
- Start run
- Log metrics
- Get run/experiment details
Just for demonstration purposes, I will create a Demo Experiment and log values 1,2,3 for metric called demo_metric.
from azureml.core import Experiment
exp1 = Experiment(workspace=ws, name="Demo_Experiment")
exp1
If you click on the above link, it will take you directly to the Azure ML Studio Experiment page. We will created the Experiment, i.e folder. Now, we run some experiments
#Start run
from azureml.widgets import RunDetails
demo_run = exp1.start_logging()
#Start Logging
demo_run.log('demo_metric' , 1)
demo_run.log('demo_metric' , 2)
demo_run.log('demo_metric' , 3)
#Stop logging
demo_run.complete()
RunDetails(demo_run).show()
Remember to use run.complete() to stop the run. A better and easier way is to use with as follows. When the run is complete, it will be completed automatically.
For the bank marketing project, we created a random forest model using default hyper params. To demonstrate how create experiments, we will train four RF models by changing the max_depth parameter. When max_depth is None, it's just a stump of a tree. As we grow the depth, features are split and will identify non-linear patterns in the data. We will try max_depth = [None, 5,7,9]. In a real project, you will perform hyperparameter optimization using RandomSearch, Baysian Optimization using SKLearn, HyperOpt, HyperDrive etc.
#Create another experiment called bank
from azureml.core import Run
#Define new experiment
bank = Experiment(workspace=ws, name="Bank_Marketing", )
#Define Hyperparameter to tune
max_depth=[None,5,7,9]
#Run the experiment
for depth in max_depth:
with bank.start_logging() as run: #snapshot only the snapshot directory snapshot_directory = 'snapshot'
#Log max_depth
run.log('Model', 'Random Forest')
run.log('Dataset', ds_uid)
run.log('max_depth', int(0 if depth is None else depth))
run.log_list("input_columns", list(x1.columns))
#train the pipeline
pipe2 = Pipeline([
('ct', ct),
('rf', RandomForestClassifier(oob_score=True,
random_state=0,
class_weight = 'balanced',
max_depth = depth )),
])
pipe2.fit(x1,y1)
rf2 = pipe2[-1]
#Log model details
run.log('oob_score', 'True')
run.log('class_weight', 'balanced')
oob_pred2 = np.argmax(rf2.oob_decision_function_,axis=1)
auc2 = metrics.roc_auc_score(y1, oob_pred2)
#Log metrics
run.log('oob_auc', auc2)
print("max_depth: ",depth," , oob_auc: ", np.round(auc2,3))
RunDetails(run).show()
By increasing the max_depth, AUC increased from 62% to 74% !
In the experiment above, we logged the model class, dataset used, hyper parameter, input columns, AUC score etc. After the experiment is complete, you can visit the Studio to see the output and/or interact with the model artifacts.
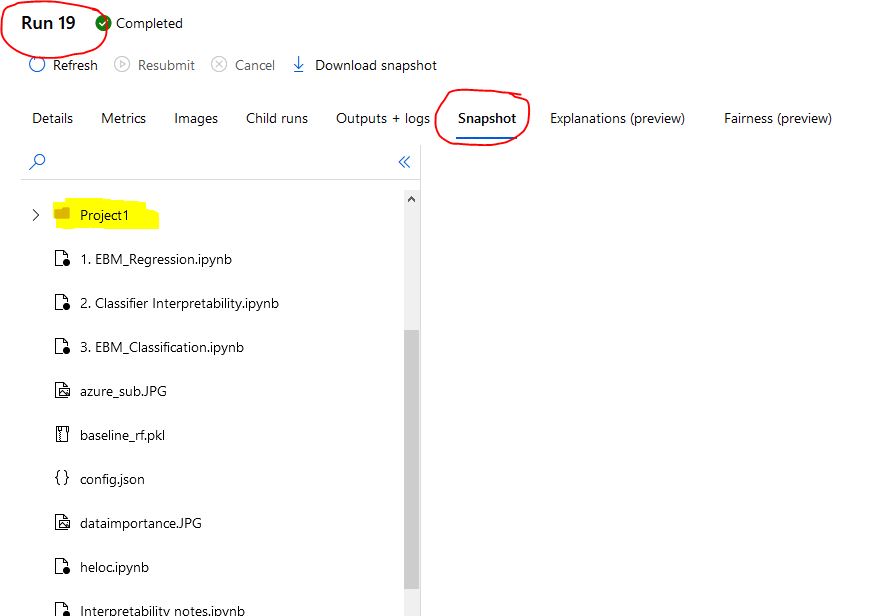
Note that by default, when you create an experiment, Azure ML will take a snapshot of the working folder. See below. Depending on your needs this is a good/bad thing. You may not want to snapshot all the files and folder. You can specify an amlingnore or gitignore file to indicate which files/folders to ignore. Another option is to specify which directory to snapshot. For example, above I specified start_logging(snapshot_directory = 'snapshot') to snapshot the snapshot folder. This helps reproducibility. You can save data, yaml, config files etc so you or your colleagues can reproduce the results months later. The maximum snapshot limit is 300MB. If your directory exceeds that the run will fail. You can increase the limit but you will incur storage costs. Also, directories ./output and ./logs are special. They will always be automatically uploaded as snapshot.
I recommending 'snapshotting' only the required model artifacts and specifying which folder to snapshot.
We ran some experiments with max_depth hyperparameters and found that using max_depth = [5,7,9] will improve the results significantly. Let's use 'one-standard error' rule (Ref: ESL, pp61) to pick a parsomonious model. We will pick max_depth=5 for create a pickle file and deploy it in service.
Model accuracy is not the only metric, in fact it shouldn't be, to select a model. Focus should be on selecting simple, parsimonious models that are interpretable & explainable. Watch my interpretability presentation for more details. For now, we will assume this is the right model for us.
final_model = Pipeline([
('ct', ct),
('rf', RandomForestClassifier(oob_score=True,
random_state=0,
class_weight = 'balanced',
max_depth = 5)),
])
final_model.fit(x1,y1)
joblib.dump(final_model, 'bank_model.pkl')
test_final_model = joblib.load('bank_model.pkl')
test_final_model.predict(x1.iloc[0:])
print("AUC on Test set: ,", np.round(metrics.roc_auc_score(y2, test_final_model.predict(x2)),2))
Excellent, OOB score is same as the test (very rare!).
There are actually multiple ways to register and deploy a model as webservice. Typically, you will first create training script, register an environment, create inference schema, register model, create deployment config etc. But there is a shorter way to do all of that in one single step. Usually you will go through everything step-by-step but for demonstration purposes, I will roll these steps into one by using ResourceConfiguration class. Also, note that this is for real-time inferencing using Azure Container Instance. You should always deploy the model locally first for debugging, testing before deploying it to the cloud. For batch-inferencing, follow these steps.
You can also register and deploy using the interface in the Studio.
We will also save the sample features and labels for future reference and model debugging.
np.savetxt('features.csv', np.array(x1), delimiter=',', fmt='%s')
np.savetxt('labels.csv', y1, delimiter=',')
datastore.upload_files(files=['./features.csv', './labels.csv'],
target_path='sample_data/',
overwrite=True)
input_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, 'sample_data/features.csv')])
output_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, 'sample_data/labels.csv')])
from azureml.core import Model
from azureml.core.resource_configuration import ResourceConfiguration
model = (Model.register(workspace = ws,
model_name = "bank_model", #name for the model
model_path = './bank_model.pkl', #Specify the .pkl file
model_framework=Model.Framework.SCIKITLEARN, #This will automatically create environment & schema
sample_input_dataset=input_dataset, #Sample input
sample_output_dataset=output_dataset, #Sample output
resource_configuration=ResourceConfiguration(cpu=1, memory_in_gb=0.5), #ACI config to use
description='Bank Marketing model to predict of customer will sign up',
tags = {'Author':'Sandeep',
'Date':'2/18/2021',
'Model':'RandomForest',
'Dataset':ds_uid}
))
print('Name:', model.name)
print('Version:', model.version)
service = Model.deploy(ws, "service3", [model])
service.wait_for_deployment(show_output=True)
service
service.state
Webservcie status is Healthy and ready to be used in production for inferencing.
import json
input = json.dumps({'data':x1.iloc[:10,:].to_dict('list'),'method': 'predict'})
headers = {'Content-Type': 'application/json'}
output = service.run(input)
output
We got the response back with predictions. Service is running and ready for action. If you are trying this example, be sure to delet the service and the weorkspace to avoid charges.
service.delete()
To monitor the performance of the webservice and the deployed model, we need to do few things:
- Stress test the model for distribution shifts and loads
-
Collect webservice performance metric using Application Insights. This will help us collect:
- Responses
- Request rates, response time, failure rates
- Exceptions
-
Monitor Concept Drift
- Performance of the ML model will likely degrade over time due to change in distribution of the input data
- By monitoring drift, we can measure the drift and decide when to re-train the model
-
Collect Model Interpretability data during inferencing
- This is to track how model is creating predictions and if predictions are fair
This is big topic and will require a separate presentation. But just know that with Azure ML service, you can monitor the model performance in production environment.
- Azure ML Pipelines
- Azure ML HyperDrive
- Azure Auto ML
- Azure ML Studio Designer
Thank you ! I hope you found this helpful. As always, feel free to get in touch if you have any questions.